(自学笔记3)门槛模型原理和stata实现
参考视频
https://www.bilibili.com/video/BV1oA4y1d7Wy/?vd_source=f2f570aebd7fdba141e44deff4319c36
门槛模型介绍
以我们初中还是高中学的分段函数理解:Y与X并不一定是线性关系,有可能在不同阶段存在拐点,有不同的斜率。而门槛模型就是研究的变量之前的非线性关系。具体的定义为:门槛效应是指当一个经济参数达到特定的数值后,引起另外一个经济参数发生突然转向其他发展形式的现象(结构突变),作为转变的临界值就称为门槛值或者门限值。
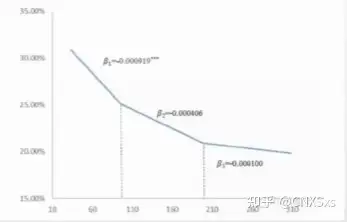
hansen(1999)首次介绍了具有个体效应的面板门槛模型的计量分析方法。该方法以残差平方和最小化为条件确定门槛值,并检验门槛值的显著性。
计量模型
常见的单门槛模型为: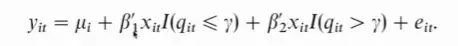
其中μ为常数项,β为系数,I(·)为示性函数,示性函数里面的q就是门槛变量,γ为门槛值。写成分段函数为: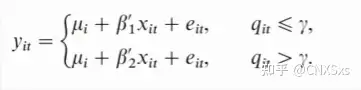
值得注意的是,q既可以是核心解释变量,比如研究收入与学历的关系,假设当学历为硕士后,学历再增长所导致的收入变化可能会更高。q也可以是与被解释变量相关的变量,比如研究收入与学历的关系时,工作年限是一个同收入具有相关性的变量,当工作年限大于十年时,学历对收入的影响可能就没那么巨大了。(门槛值就是工作年限为10年)
门槛值的确定
懒得打字了,stata会自动计算好。

确定门槛值之后还要进行显著性检验,为了检验以门槛值划分的样本组其模型估计参数是否显著不同。
LM统计量就是拉格朗日统计量,是检验模型中对于参数的约束是否合理,想具体了解可参照
https://zhuanlan.zhihu.com/p/389052529
当确定变量存在门槛效应后,再进一步确定其置信区间(stata会进行操作)
stata操作
国内常用的面板门槛命令普遍采用王群勇和连玉君老师的命令。
连玉君老师:
xtthres y x ,thres(q) dthres(z) min(#) bs1(#) bs2(#) bs3(#)
其中y为被解释变量;x为解释变量(不受门槛变量影响的变量);thres(q) q为门槛变量;
dthres(z)z为受到门槛变量影响的解释变量;min(#)指定在搜索每个区域中的最小观测数,默认值为10;bs1(#) bs2(#) bs3(#)分别在单阈值、双阈值和三阈值模型中自抽样次数,默认值都是300.
王群勇老师:
xthreg y x rx(var) qx(var) thnum(#) grid(#) trim(numlist) bs(numlist)
其中y为被解释变量;x为解释变量(不受门槛变量影响的变量);rx()是放入受到门槛变量影响的解释变量;qx()是门槛变量;thnum()是几个门槛值;trim()是对门槛变量两端的值进行缩尾;grid()是缩短运行时间,bs()是自抽样估计量的值和标准误差(抽样次数)
门槛模型画图命令

做门槛效应的步骤
1.导入数据,定义面板数据 xtset id year
2.对变量进行单位根检验:用以检验变量的平稳性,如果序列中存在单位根过程不平稳,就会使回归分析中存在伪回归。如果数据平稳就是进行门槛模型检验,单位根检验的命令如下: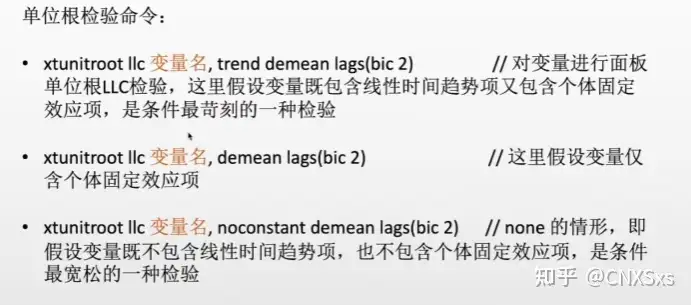
以Hansen1999的数据为例,i 为被解释变量,c1是核心解释变量(受门槛变量影响的解释变量),d1是门槛变量“q1 q2 q3 d1 qd1”为控制变量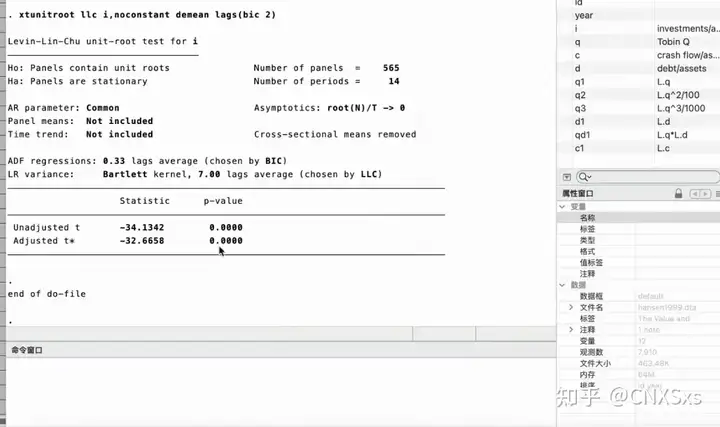
通过看p-value判断是否符合显著性,p显著,数据是平稳的。然后执行门槛命令
xthreg i q1 q2 q3 d1 qd1, rx(c1) qx(d1) thrum(1) grid(400) trim(0.01) bs(3) ///单门槛检验 bs抽样次数可自行更改,一般300或者500都行
结果解读:一般报告以下内容
门槛值

门槛值的显著性水平

回归结果
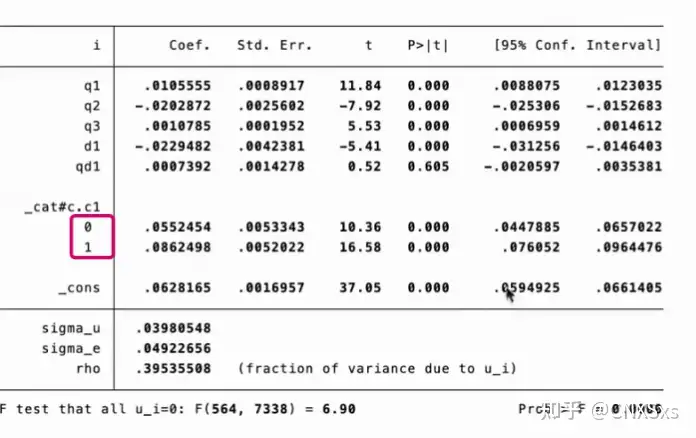
左侧小方块中的0表示小于门槛值的结果,1表示大于门槛值的结果
一般来说论文中不能用0和1,可以先用asdoc加门槛命令输出结果到word,然后改为
c1(d1≤0.015)
c1(d1>0.015)
画图
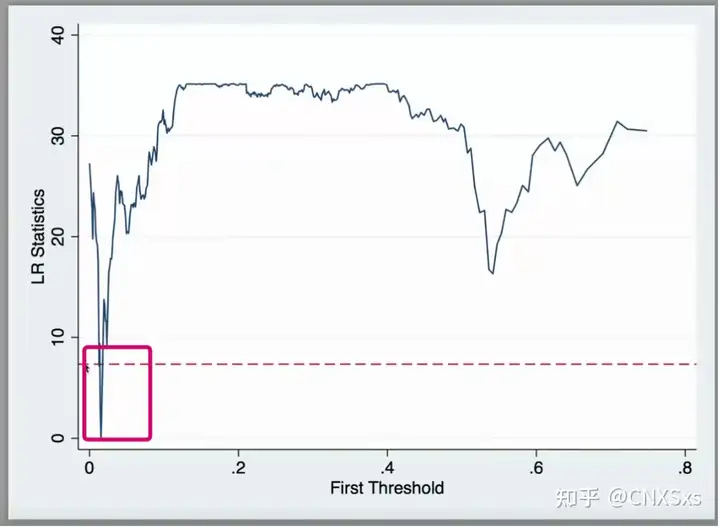
结果解读:看曲线是否有虚线以下的部分,如果有,说明通过了置信区间的检验
双门槛检验
xthreg i q1 q2 q3 di qd1, rx(c1) qx(d1) thnum(2) grid(400) trim(0.01 0.01) bs(3 3)
双门槛就是在单门槛命令的基础上,写两个缩尾,两个抽样次数
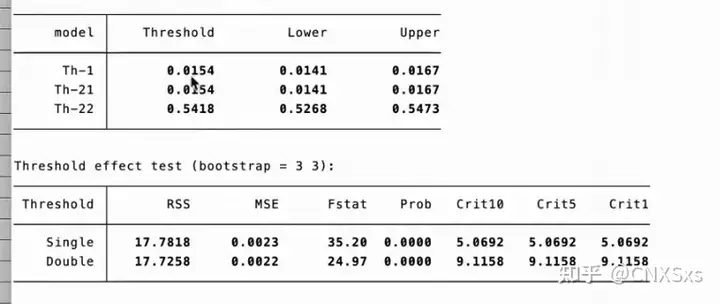
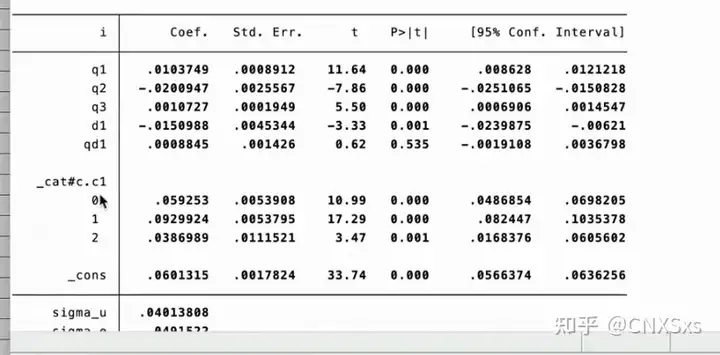
结果解释和画图参考单门槛
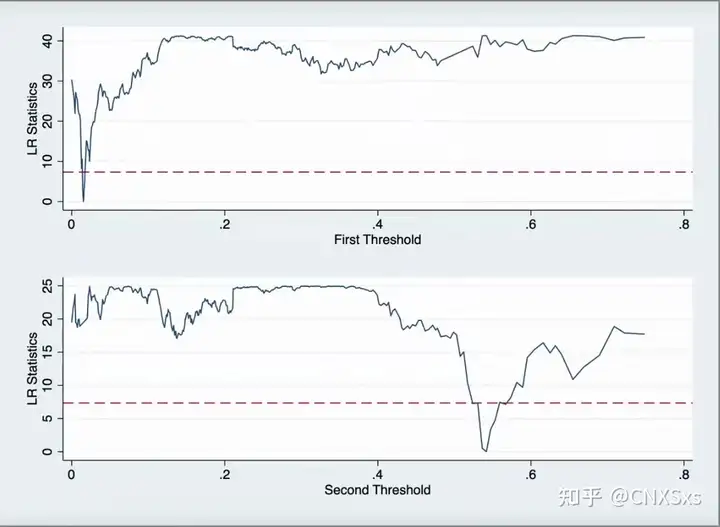
可以看到一个门槛值是0.0154,另一个门槛值是0.5418
三门槛同理,注意门槛值的顺序要按照大小排列。
发布于 2023-03-28 18:51